
July 20, 2026
What Is Ransomware Recovery Attestation? An Elastio Framework for Documenting a Clean Restore Point
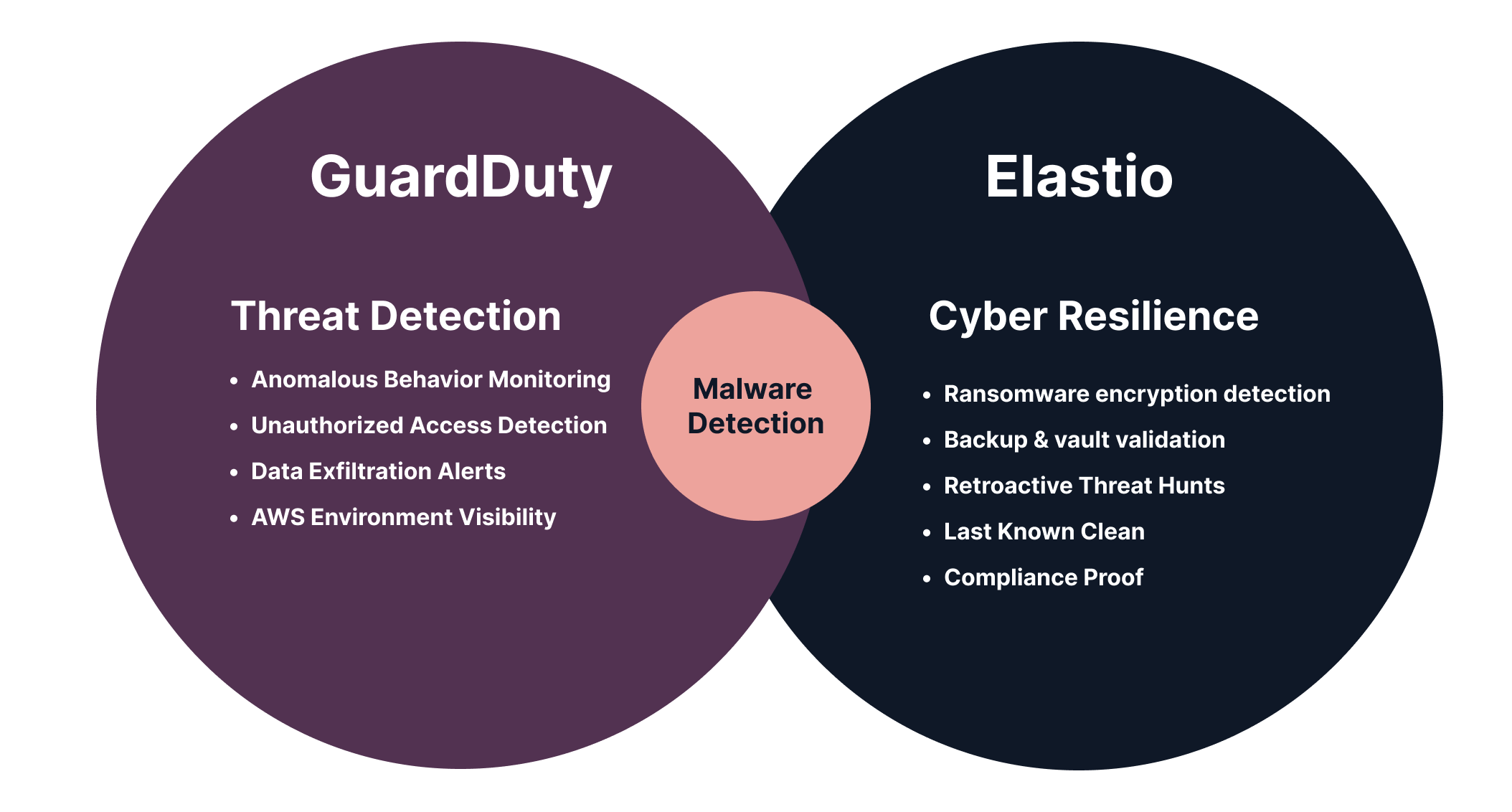
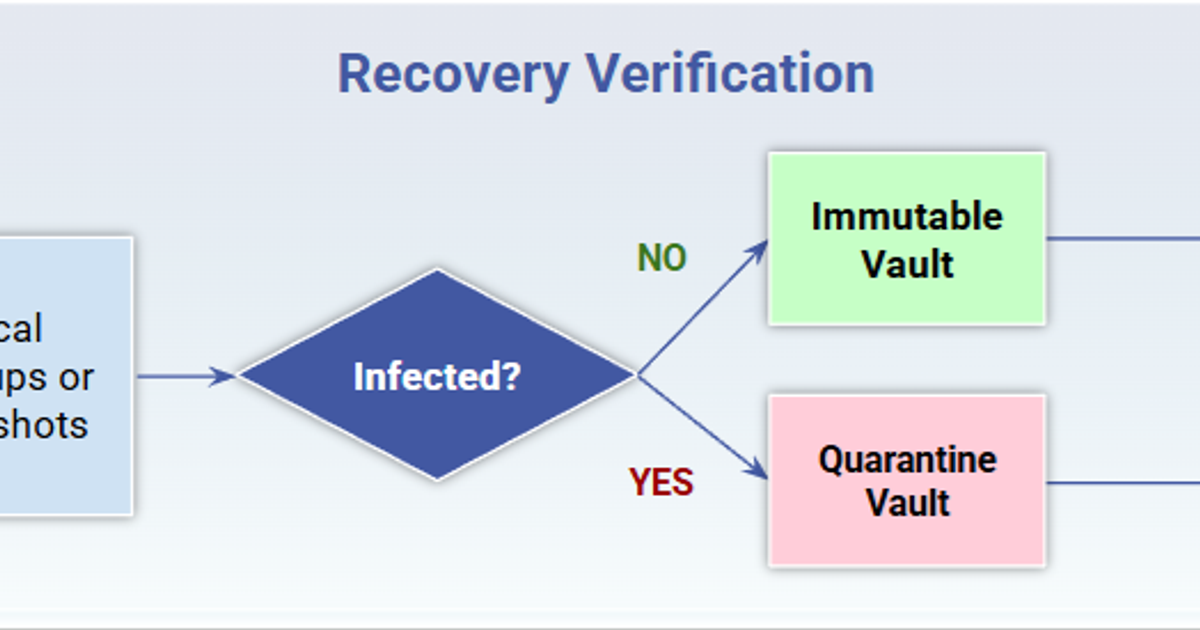
The question that ends most board cyber briefings is not “Do we have backups?” It is “How do you know you can actually recover?” The honest answer from most security teams is a backup success rate and a last DR test date. Neither one proves that the recovery point you would restore from today is free of ransomware. Recovery attestation closes that gap. A recovery attestation is documented proof that a specific recovery point passed content-integrity inspection with no supported indicators of ransomware detected, tied to an asset and a timestamp, and that its candidate clean point was confirmed by isolated restore testing. It is the evidence a CISO can put in front of a board, an audit committee, a regulator, or an insurer without reconstructing anything under deadline. Definition A recovery attestation is documented proof that a specific recovery point passed content-integrity inspection with no supported indicators of ransomware detected, tied to an asset and a timestamp, and that its candidate clean point was confirmed by isolated restore testing. This is an Elastio framework, not settled industry terminology. Regulators require you to test recovery and validate the integrity of restored data. They do not use the phrase “recovery attestation,” and no standards body has ratified it as a defined term. We use it because the market lacks a clean name for the artifact that answers the board’s real question, and because the artifact is what our platform produces after every hunt cycle. Attestation is the evidence artifact, not the capability Recovery assurance and recovery attestation are related but distinct. Our recovery assurance work is the operational capability: continuous content-integrity inspection of recovery points across live data, replicated data, and backups, paired with isolated restore testing of the candidate clean point. Recovery attestation is the artifact that capability produces. Assurance is the machine. Attestation is the receipt. A capability with no artifact cannot survive an audit. A team can run continuous validation and still fail a DORA resilience review or an insurance renewal if it has no dated, asset-level record it can hand over. Attestation is what turns an internal control into external evidence. What a recovery attestation actually contains Treat an attestation as a compliance object, not a marketing claim. To be usable as board or audit evidence, it needs concrete fields: Asset identity. The specific system, volume, database, or workload the recovery point belongs to, not a vault name. Recovery point and timestamp. Which point in time was inspected, and when the inspection ran. Verdict. Clean or compromised, with the finding detail if compromised. Method. How the verdict was reached. In Elastio’s case, Deep File Inspection by the Hunt Engine, which opens and inspects inside each file rather than reading metadata, entropy scores, or backup job status. Clean boundary. The dividing line in time between recovery points that are verified clean and those that are not, so recovery decisions have a floor. Chain of evidence. A retained log a third party can review, so the attestation is auditable after the fact. A backup success report has none of these except a timestamp. It confirms a copy completed. It says nothing about whether the data inside that copy was already encrypted or carrying a dormant payload when the job ran. Why “the backup succeeded” is not attestation The failure mode plays out the same way in most incidents. The backup jobs are green. The storage is immutable. Then the team restores a recovery point and reintroduces the same ransomware that caused the outage, because the malware was already present when that point was written. Immutability protected the copy from deletion. It never proved the contents were clean. A green job status and an object-lock flag are two facts about the copy. Neither is a verdict on the data, and a board asking whether you can recover is asking for the verdict. An attestation is worth the most when it exists before you need it. A regulated auto insurance firm running Veeam had Elastio inspecting its backups every day , so the dated clean-or-compromised record for each recovery point already existed when a compromised document surfaced inside a backup. The firm did not have to reconstruct evidence under deadline; the attestation was a standing artifact, refreshed each cycle, rather than a report someone assembles after the audit committee asks. That is the operational shape of attestation: a running record the audit request reads, already written before the request arrives. Where the evidence is actually used Recovery attestation is not a compliance requirement by name. It is the artifact that satisfies recovery-integrity expectations that already exist in the primary texts. NIST SP 800-184, Guide for Cybersecurity Event Recovery (Bartock et al., December 2016), frames recovery as a process that must be planned, tested, and improved, with recovery decisions grounded in verified system and data state rather than assumption. An attestation is the record of that verification for a given recovery point. For EU financial entities, DORA Article 12 (Regulation (EU) 2022/2554) requires documented backup and restoration procedures, ICT systems that are physically and logically segregated from the source, and data-integrity checks during recovery, including multiple checks and reconciliations. A dated, asset-level clean-or-compromised record helps satisfy that obligation by supplying evidence those checks ran, where a written procedure only shows they were planned. Under NYDFS 23 NYCRR 500 , covered entities must maintain recovery capability and, under Section 500.17, provide an annual certification of compliance. A continuous evidence log of recovery-point integrity supports that certification without reconstructing it from memory the week before it is due. The SEC cybersecurity disclosure rules (Release Nos. 33-11216; 34-97989, adopted July 26, 2023) require disclosure of a material cybersecurity incident on Form 8-K within four business days of a materiality determination, plus periodic disclosure of risk-management processes under Regulation S-K Item 106. The rules do not require recovery attestation. Attestation data may support the Item 106 risk-management disclosure by documenting the recovery-integrity process, and it can help scope impact for the incident timeline. For healthcare, HIPAA’s contingency plan standard at 45 CFR 164.308(a)(7) requires a data backup plan, a disaster recovery plan, and procedures for periodic testing and revision. It does not name content inspection. Attestation records can be used to demonstrate the testing and integrity work behind that standard on an ongoing basis, not once a year. None of these rules names recovery attestation as a requirement. Each one obliges you to plan, test, or disclose recovery-integrity work, and a dated attestation is evidence that the work happened. From attestation to a board pack The board does not need the raw log. It needs a short, defensible summary drawn from it. A recovery attestation reduces to a handful of numbers a director can act on: Percentage of critical assets under continuous inspection. Age of the last-known clean recovery point for the most critical systems. Number of active threats found in recovery data this period. The clean boundary for the systems that would carry the business through an outage. Those numbers replace the two answers boards usually get, backup success rate and last test date, with a statement about whether the organization can recover to a clean state today. That is a materially different claim, and it is one the CISO can defend under questioning because it traces back to dated, asset-level evidence rather than a plan on a shelf. The gap most teams discover here is that they have the capability conversation but not the artifact. They can describe continuous validation. They cannot produce a recovery point, a timestamp, and a verdict when the audit committee asks for one specific system. If you want to see what that evidence looks like against your own environment, our Recovery Assessment runs against an existing backup estate and returns the last-known clean recovery point per service and where the gaps are. Bring the output to your next board or audit meeting and answer the recovery question with a document instead of a promise. See your last-known clean recovery point Our Recovery Assessment runs against your existing backup estate and returns the last verified-clean recovery point per service, plus where the gaps are. Bring the output to your next board or audit meeting. Run a Recovery Assessment Sources [1] NIST, SP 800-184: Guide for Cybersecurity Event Recovery , Bartock, Cichonski, Souppaya, Smith, Witte, Scarfone, December 2016 [2] European Union, Regulation (EU) 2022/2554 (DORA), Article 12: Backup policies and procedures, restoration and recovery procedures and methods , 2022 [3] New York State Department of Financial Services, 23 NYCRR Part 500: Cybersecurity Requirements for Financial Services Companies [4] U.S. Securities and Exchange Commission, Cybersecurity Risk Management, Strategy, Governance, and Incident Disclosure: Small Entity Compliance Guide , 2023 [5] U.S. Department of Health and Human Services, 45 CFR 164.308: Administrative safeguards (HIPAA Security Rule) [6] Elastio, How an auto insurance firm proved backup integrity before an attack
Read post →








-1-1200x630.jpg)
-1200x630.png)



-1-1200x630.jpg)