
The Accuracy Gap: Why Anomaly and Entropy Detection Fail the Ransomware Resilience Lifecycle

The False Security of Checked BoxesIn the high-stakes world of cyber-recovery, there is a dangerous assumption that "detection" is a binary state, either you have it or you don’t. Most backup vendors have checked the box by offering anomaly and entropy-based monitoring. But as a CISO who has spent over a decade in regulated industries, I’ve learned that a check-box control is often worse than no control at all. It creates a false sense of security while delivering a signal so noisy and inaccurate that it’s practically unusable. |
The Inaccuracy Problem: Inference Is Not Evidence
The core issue with the ransomware detection provided by backup vendors isn’t just where it happens; it’s how it happens. These tools rely on statistical inference rather than data evidence:
- Anomaly Detection: Monitors for “unusual” behavior, like a sudden spike in changed blocks or a deviation in backup window duration.
- Entropy Detection: Measures data randomness to infer encryption.
In a modern enterprise, data is naturally “noisy.” Compressed database logs, encrypted video files, and standard application updates all register as anomalies or high-entropy events. Because these tools cannot distinguish between a legitimate .zip file and a ransomware-encrypted .docx, they produce a constant stream of false positives.
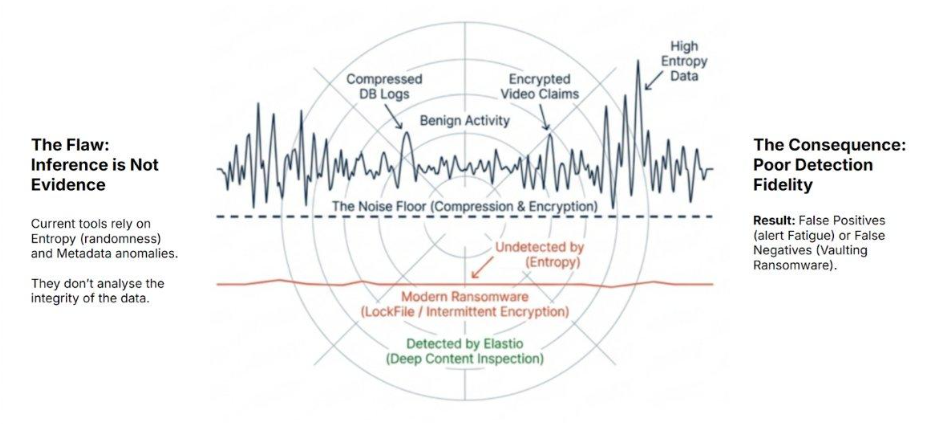
Figure 1: Modern ransomware (red) operates below the statistical noise floor while legitimate enterprise data generates constant false-positive noise. Elastio detects threats through structural content inspection, independent of entropy.
For a SOC team, this noise is toxic. When a tool is consistently inaccurate, the human response is predictable: the alerts are muted, tuned down, or ignored. If your “last line of defense” relies on a signal that your team doesn’t trust, you don’t actually have a defense.
Beyond the “Big Bang”: The Rise of Evasive Encryption
Current anomaly and entropy tools were designed for the "Big Bang" encryption events of years past. As of 2026, threat actors have evolved well beyond this model, with variants including LockFile specifically engineered to stay below the statistical noise floor using intermittent encryption.
- Intermittent Encryption: Encrypting every other 4KB block so the overall entropy change remains negligible.
- Low-Entropy Encryption: Using specialized schemes that mimic the statistical signature of benign, compressed data.
- Selective Corruption: Attacking only file headers or metadata while leaving the bulk of the file statistically “normal.”
Against these techniques, a statistical guess is useless. You need a Data Integrity Control that performs deep content inspection to validate the actual structure of the data, not just its randomness.
Mapping Integrity to the Resilience Lifecycle
A high-fidelity integrity engine, like Elastio, provides the same level of accuracy regardless of where it is deployed. However, for a CISO, the location of that check is a strategic decision based on the Resilience Lifecycle:
- The Backup Layer: Validating integrity here is non-negotiable. It ensures that when you hit “restore,” you aren’t re-injecting corrupted data into your environment and extending downtime.
- The Production Layer (VMs, Buckets, Filers): For mission-critical data, waiting for the backup cycle to run is a luxury we can’t afford. Detecting corruption at the source, in your production VMs, S3 buckets, or filers, is about minimizing the blast radius.
Data integrity validation serves different purposes depending on where it is applied in the resilience lifecycle. Scanning production data across VMs, filers, and object stores is the most effective way to minimize blast radius and prevent spread, because it detects corruption before it propagates downstream.
When production data cannot be scanned due to security boundaries, operational constraints, or tenancy limitations, snapshots and replicas become the practical control point for achieving the same outcome. In this model, snapshot integrity analysis is not additive to production scanning; it is a substitute. Both serve the same objective: early detection and containment before corruption reaches backups or immutable storage.
The CISO’s Bottom Line: Proving vs. Guessing
Resilience is measured by the speed and certainty of recovery. Anomaly and entropy-based detection fail on both counts: they are too inaccurate to provide certainty and too late to provide speed.
True resilience requires moving from statistical inference to data integrity validation. Whether validating backups to prove recoverability or monitoring production data to prevent spread, the objective is the same: replace guessing with proof. In regulated environments, “recovery is safe” is the only defensible statement a CISO can make to the board.
The ability to detect these advanced threats early is the difference between being able to ensure fast recovery versus a ransomware event that results in devastating downtime, data loss, and financial impact.
Can you prove your recovery points are clean?
Your board will ask if you can recover clean. This checklist lets you answer with evidence.


