
Elastio × AWS GuardDuty — Automated scans triggered by GuardDuty malware findings
GuardDuty’s release of malware scanning on AWS Backup is an important enhancement to the AWS ecosystem, reflecting growing industry recognition that inspecting backup data has become a core pillar of cyber resilience.
But real-world incidents show that ransomware often leaves no malware behind, making broader detection capabilities for encryption and zero-day attacks increasingly essential.
Across industries, there are countless examples of enterprises with premium security stacks in place - EDR/XDR, antivirus scanners, IAM controls - still suffering extended downtime after an attack because teams couldn’t reliably identify an uncompromised recovery point when it mattered most. That’s because ransomware increasingly employs fileless techniques, polymorphic behavior, living-off-the-land tactics, and slow, stealthy encryption. These campaigns often reach backup and
replicated copies unnoticed, putting recovery at risk at the very moment organizations depend
on it.
As Gartner puts it:
Modern ransomware tactics bypass traditional malware scanners, meaning backups may appear ‘clean’ during scans but prove unusable when restored. Equip your recovery environment with advanced capabilities that analyze backup data using content-level analytics and data integrity validation.”
— Gartner, Enhance Ransomware Cyber Resilience With A Secure Recovery Environment, 2025
This is the visibility gap Elastio was designed to close.
In this post, we walk through how Elastio’s data integrity validation works alongside AWS GuardDuty to support security and infrastructure teams through threat detection all the way to recovery confidence and why integrity validation has become essential in the age of identity-based and fileless attacks.
What is AWS GuardDuty?
AWS GuardDuty is a managed threat detection service that continuously monitors AWS environments for malicious or suspicious activity. It analyzes signals across AWS services, including CloudTrail, VPC Flow Logs, DNS logs, and malware protection scans, and produces structured security findings.
GuardDuty integrates natively with Amazon EventBridge, which means every finding can be consumed programmatically and routed to downstream systems for automated response.
For this integration, we focus on GuardDuty malware findings, including:
- Malicious file findings in S3
- Malware detections in EC2 environments
These findings are high-confidence triggers that indicate potential compromise and warrant immediate validation of recovery data.
Why a GuardDuty Finding Should Trigger Recovery Validation
Malware detection is important, but it is no longer sufficient to validate data recoverability.
Identity-based attacks dominate cloud breaches
Today’s attackers increasingly rely on stolen credentials rather than exploits. With valid identities, they can:
- Use legitimate AWS APIs
- Access data without dropping malware
- Blend into normal operational behavior
In these scenarios, there may be nothing malicious to scan, yet encryption or tampering can still occur.
Fileless and polymorphic ransomware evade signatures
Many ransomware families:
- Run entirely in memory
- Continuously mutate their payloads
- Avoid writing recognizable artifacts to disk
Signature-based scanners may report “clean,” even as encryption spreads.
Zero-day ransomware has no signatures
By definition, zero-day ransomware cannot be detected by known signatures until after it has already caused damage - often widespread damage.
The result is a dangerous failure mode: backups that scan clean but restore encrypted or corrupted data.
Why Integrity Validation Changes the Outcome
Elastio approaches ransomware from the impact side.
Instead of asking only “is malware present?”, Elastio validates:
- Whether encryption has occurred
- What data was impacted
- When encryption started
- Which recovery points are still safe to restore
The timeline above reflects a common real-world pattern:
- Initial access occurs quietly
- Encryption begins days or weeks later
- Backups continue, unknowingly capturing encrypted data
- The attack is only discovered at ransom time
Without integrity validation, teams cannot know with confidence that their backups will work when they need them. This intelligence transforms a GuardDuty finding from an alert into an actionable recovery decision.
Using GuardDuty as the Trigger for Recovery Validation
Elastio’s new GuardDuty integration automatically initiates data integrity scans when GuardDuty detects suspicious or malicious activity.
Instead of stopping at alerts, the integration immediately answers the implied next question: Did this incident affect our data, and can we recover safely?
By validating backups and recovery assets in response to GuardDuty findings, Elastio reduces response time, limits attacker leverage, and enables faster, more confident recovery decisions.
Architecture Overview
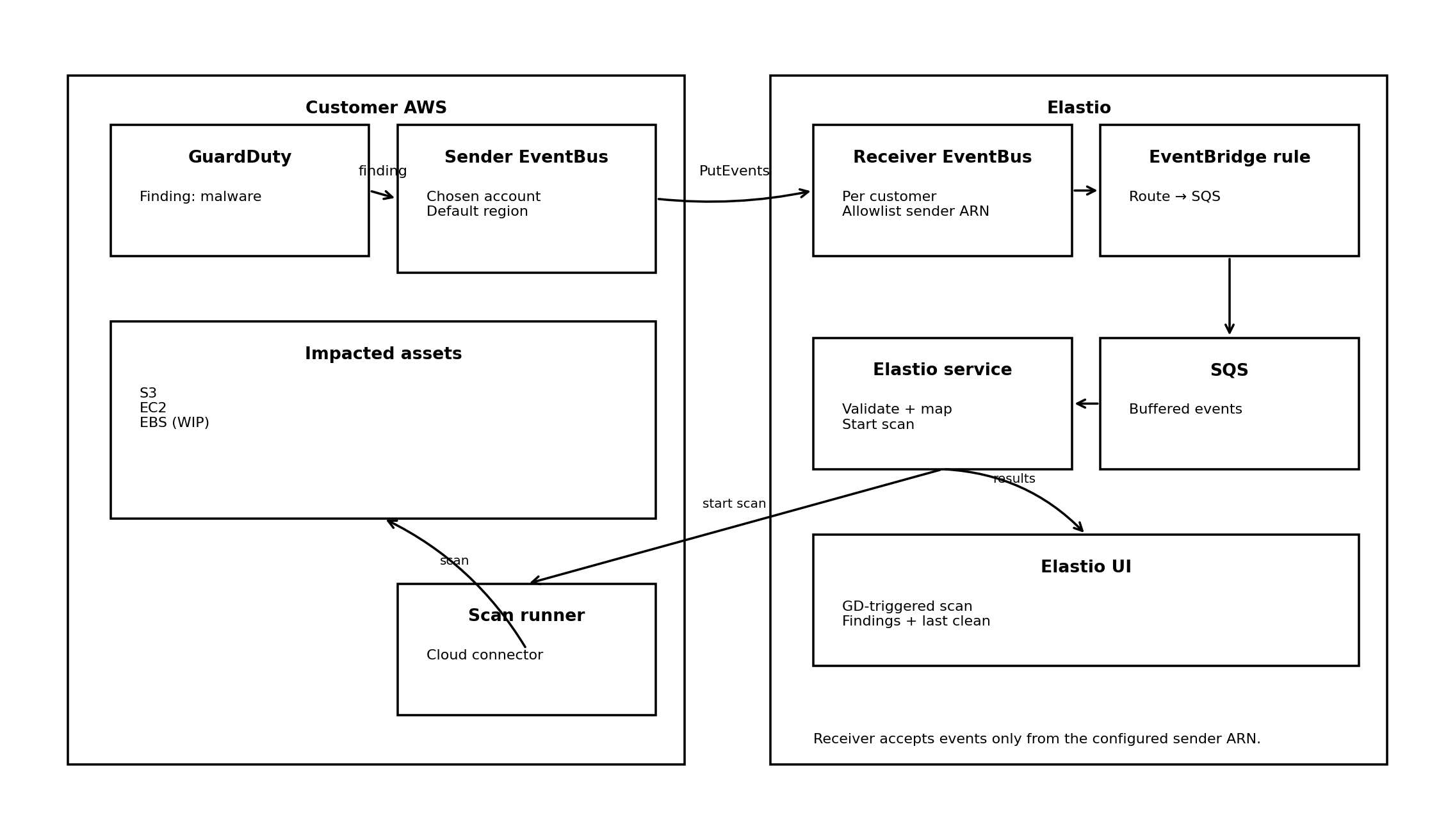
At a high level:
- GuardDuty generates a malware finding
- The finding is delivered to EventBridge
- EventBridge routes the event into a trusted sender EventBus
- Elastio’s receiver EventBus accepts events only from that sender
- Elastio processes the finding and starts a targeted scan
- Teams receive recovery-grade intelligence
Including:
Ransomware detection results
File- and asset-level impact
Last known clean recovery point
Optional forwarding to SIEM or Security Hub
The critical design constraint: trusted senders
Each Elastio customer has a dedicated Receiver EventBus. For security reasons, that receiver only accepts events from a single allowlisted Sender EventBus ARN.
This design ensures:
- Strong tenant isolation
- No event spoofing
- Clear security boundaries
To support scale, customers can route many GuardDuty sources (multiple accounts, regions, or security setups) into that single sender bus. Elastio enforces trust at the receiver boundary.
End-to-End Flow
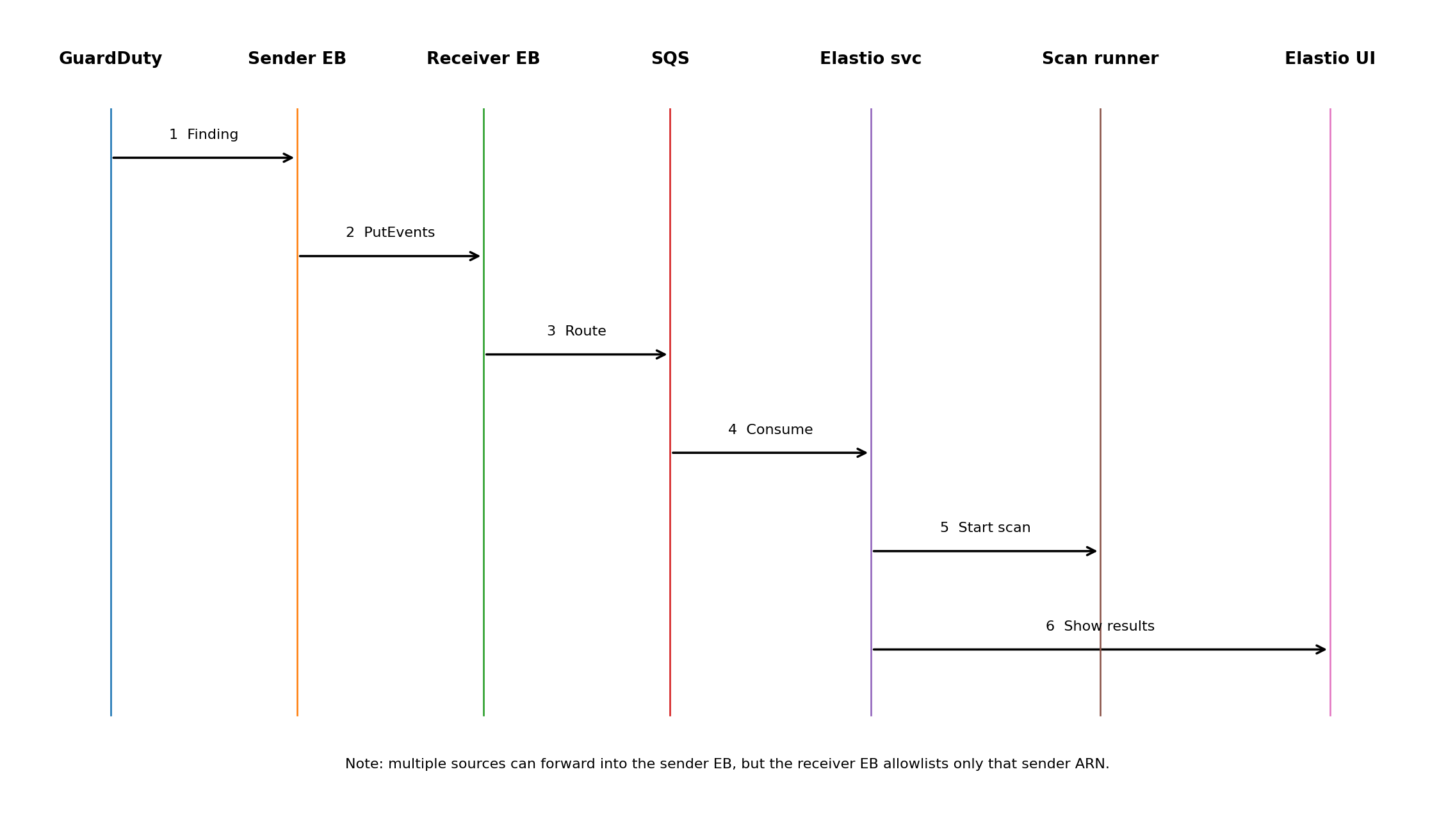
Step 1: GuardDuty detects malware
GuardDuty identifies a malicious file or suspicious activity in S3 or EC2 and emits a finding.
Step 2: EventBridge routes the finding
Native EventBridge integration allows customers to filter and forward only relevant findings.
Step 3: Sender EventBus enforces trust
All GuardDuty findings flow through the designated sender EventBus, which represents the customer’s trusted identity.
Step 4: Elastio receives and buffers events
The Elastio Receiver EventBus routes events into an internal queue for resilience and burst handling.
Step 5: Elastio validates recovery data
Elastio maps the finding to impacted assets and initiates scans that analyze both malware indicators and ransomware encryption signals.
Step 6: Recovery-grade results
Teams receive actionable results:
- Ransomware detection
- File-level impact
- Last known clean recovery point
- Optional forwarding to SIEM or Security Hub
What This Enables for Security and Recovery Teams
By combining GuardDuty and Elastio, organizations gain:
- Faster response triggered by high-signal findings
- Early detection of ransomware encryption inside backups
- Reduced downtime and data loss
- Confidence that restores will actually work
- Audit-ready evidence for regulators, insurers, and leadership
Supported Today
- S3 malware findings
- EC2 malware findings
EBS-specific handling is in progress and will be added as it becomes available.
Why This Matters in Practice
In most ransomware incidents, the challenge isn’t identifying a security signal - it’s understanding whether that signal corresponds to meaningful data impact, and what it implies for recovery.
Security and infrastructure teams often find themselves piecing together information across multiple tools to assess whether encryption or corruption has reached backups or replicated data. That assessment takes time, and during that window, recovery decisions are delayed or made conservatively.
By using GuardDuty findings as a trigger for integrity validation, customers introduce earlier visibility into potential data impact. When suspicious activity is detected, Elastio provides additional context around whether recovery assets show signs of encryption or corruption, and which recovery points appear viable.
This doesn’t replace incident response processes or recovery testing, but it helps teams make better-informed decisions sooner, particularly in environments where fileless techniques and identity-based attacks limit the effectiveness of traditional malware scanning.
Extending GuardDuty From Detection Toward Recovery Readiness
GuardDuty plays a critical role in surfacing high-confidence security findings. Elastio extends that signal into the recovery domain by validating the integrity of data organizations may ultimately depend on to restore operations.
Together, they help teams bridge the gap between knowing an incident may have occurred and assessing recovery readiness, with supporting evidence that can be shared across security, infrastructure, and leadership teams.
For organizations already using GuardDuty, this integration provides a practical way to connect detection workflows with recovery validation without changing existing security controls or response ownership.
Watch our discussion: Understanding Elastio & AWS GuardDuty Malware Scanning for AWS Backup
An open conversation designed to answer customer questions directly and help teams understand how these technologies work together to strengthen recovery posture.
- How signature-based malware detection compares to data integrity validation
- Real-world scenarios where behavioral and encryption-based detection matters
- How Elastio extends visibility, detection, and recovery assurance across AWS, Azure, and on-prem environments
- An early look at Elastio’s new integration launching at AWS re:Invent
Can you prove your recovery points are clean?
Your board will ask if you can recover clean. This checklist lets you answer with evidence.


