Monolithic data lakes are no longer the single source of truth in an enterprise, leaving prescriptive data protection tools failing to keep up. Today’s environments have data distributed across many locations. The trend towards serverless, cloud-agnostic microservices requires a new approach to data protection. Applications are becoming more complex and touch many pieces of data making automation of processes critical to maintaining operational control.
Microdata and the Microservice
For example, software developers insist on keeping “microdata” close to the microservice, which creates another data set that needs to be managed and protected. Data protection strategies have failed to keep up with the proliferation of these data reservoirs across clouds.
Government regulations and industry compliance demand that Personally Identifiable Information (PII) be protected at rest and in transit. These regulations are warranted as there are growing networks of organized criminal activity focused on exploiting companies’ data, which has become valuable intellectual property (IP).
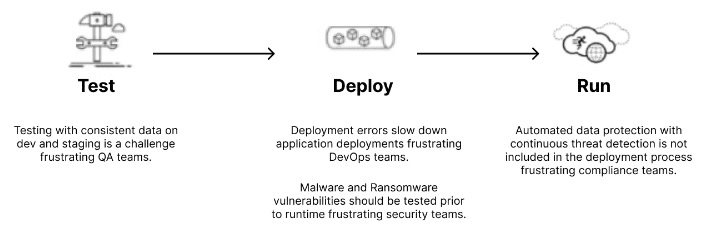
Historically, data protection has been treated as an “operations issue” to be dealt with during the run” stage of the Plan-Build-Run lifecycle. During the build stage, sample data is used as a placeholder. These “abstract artifacts” provide “form” to the function and grace of software code.
Software developers write code using assumptions based on these abstract artifacts; they often give little to no concern to the production data itself; that is “somebody else’s problem.” This “somebody else’s problem” extends to SaaS platforms where “somebody else” maintains critical enterprise data with unknown data governance standards.
Software Dev Industry Trends
Industry trends are moving towards increased software development agility in the cloud with anonymous and container-based microservices for short and long-lived processes. Business logic is decoupled from the data warehouse, so enterprises, both small and large, legacy and cloud-native, must rethink their data protection strategies. Today’s software developers update applications in real-time with data that can’t be assumed to be “someone else’s problem” any longer.
Automated Data Protection (ADP) is the process of protecting data during any stage of the Pipeline, with no impact on velocity. ADP protects data where it resides and protects data against ransomware without affecting production performance. ADP assures that the triad of Governance, Compliance, and Risk Management are met through immutable, automated and verified backups.
How Elastio Can Help During The “Data Protection” Stage
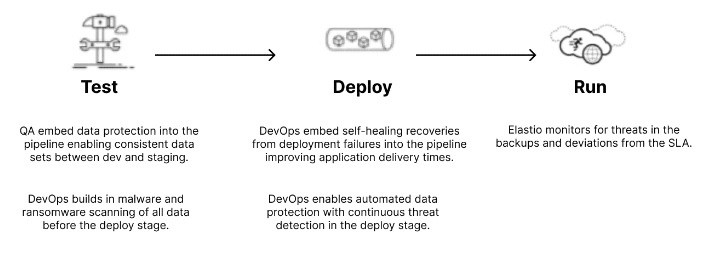
By introducing a “data protection” stage in the CI/CD Pipeline, Elastio automatically: Creates immutable data backups during sprints rather than at the end of a lifecycle. Provides native protection within the CI/CD pipeline, so data is perpetually protected. Supports IaC such as Terraform and Cloudformation and supports shell and python-based pipeline execution.
Elastio iScan discovers ransomware in the backups, thereby relieving the production systems of unnecessary overhead. Supporting all major clouds, your legacy and cloud-native solutions are protected. With an open architecture, Elastio enables easy SaaS protection for your DevOps team, developers, or other IT teams.
About Elastio
Elastio detects and precisely identifies ransomware in your data and assures rapid post-attack recovery. Our data resilience platform protects against cyber attacks when traditional cloud security measures fail.
Elastio’s agentless deep file inspection continuously monitors business-critical data to identify threats and enable quick response to compromises and infected files. Elastio provides best-in-class application protection and recovery and delivers immediate time-to-value.